
 MENU
MENU 

Two solutions for GPU efficiency can boost AI performance
Chowdhury’s lab multiplied the number of jobs a GPU cluster can finish in a set amount of time

 Enlarge
EnlargeGraphics Processing Units (GPUs) have been getting a big workout from new advancements in AI. Now the platform of choice for the machine learning methods collectively called deep learning, GPUs offer significant performance boosts thanks to their parallel computing capabilities.
GPUs are employed by large computing clusters for both training and inference, the two primary operations necessary for deep learning applications. The training step runs a neural network model through tests on huge datasets, preparing it for the real-time inference needed in the real world to recognize images, spoken words, a blood disease, or suggest the jeans someone is likely to buy next.
In dealing with huge datasets, it is also common to distribute deep learning over multiple GPUs in parallel. Achieving cost-effectiveness in these clusters relies on efficiently sharing resources between multiple users.
Naturally, this can lead to a host of problems and inefficiencies – modern GPU hardware, deep learning frameworks, and cluster managers are not designed for efficient, fine-grained sharing of GPU resources at either the micro or macro scale. Memory and computation power are regularly wasted at the level of individual GPUs and at that of an entire GPU cluster.
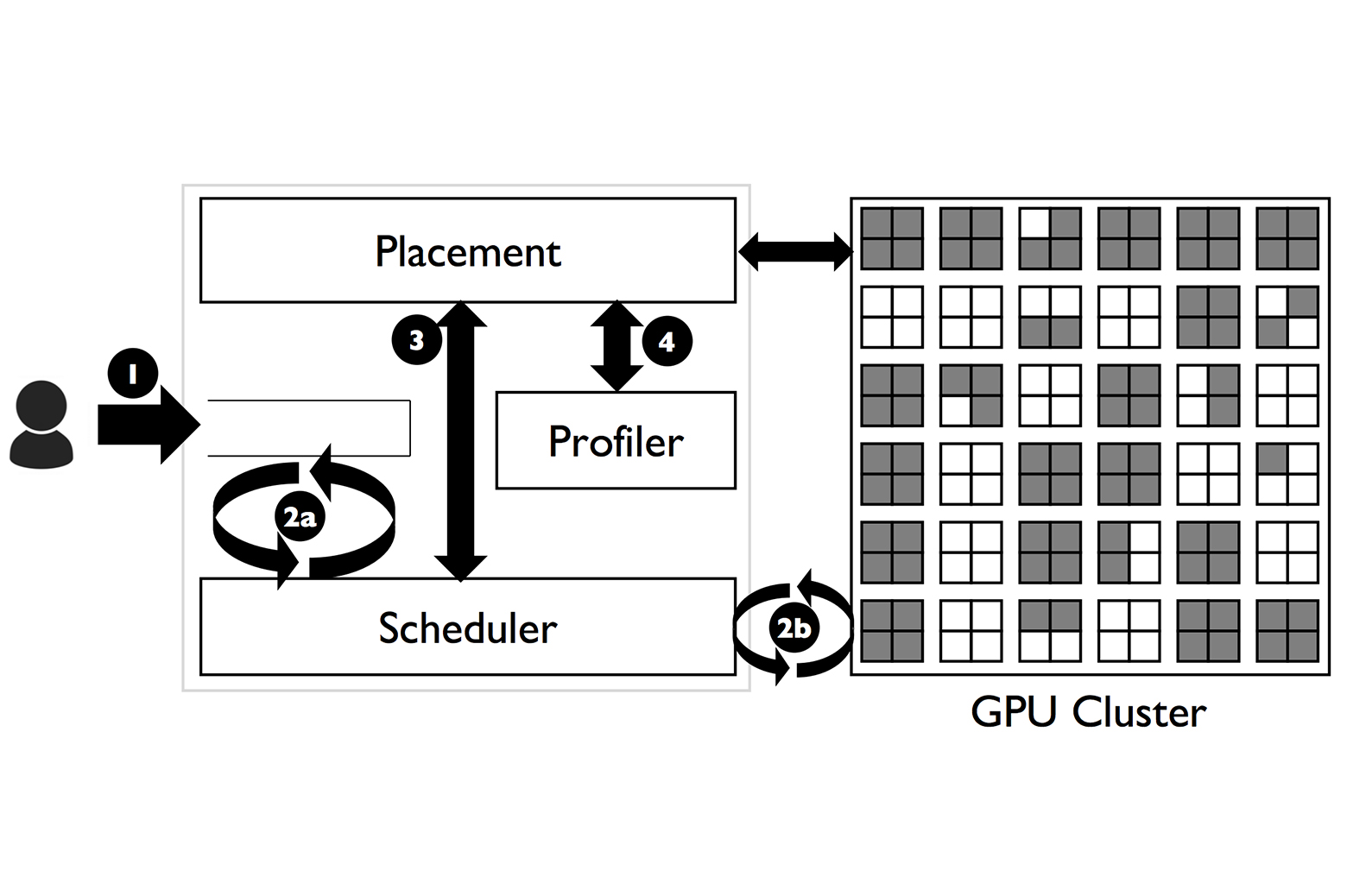
Prof. Mosharaf Chowdhury and his students, Juncheng Gu and Peifeng Yu, are working to overcome both of these shortcomings, multiplying the number of jobs a cluster can finish in a set amount of time and streamlining methods of sharing resources on the fly. In two papers, one published in February at NSDI, and another released as an open-source system, the team have described a set of solutions to achieve efficient GPU resource sharing at multiple scales: both within a single GPU (with a system called Salus) and across many GPUs in a cluster (with a system called Tiresias).
Initial benchmarking suggests the systems can result in up to 7× potential improvement over state-of-the-art solutions in terms of an individual GPU’s memory utilization, and up to 5.5× improvement in terms of job completion times in a large GPU cluster.
Tiresias – led by Juncheng Gu, who is co-advised by Prof. Kang Shin – tackles the fundamental problem of job scheduling, which has long persisted even before distributed deep learning systems were at issue. You have a very large amount of computer memory or computation power, and there are many users submitting jobs that want some portion of those resources – how do you figure out in which order to schedule the jobs, and how to allocate resources efficiently?
The problem of GPU allocation exacerbates this framework with two additional constraints. First, when a job requests a certain number of GPUs to run its operations, it won’t run at all unless it receives the full amount. That also means that while the job is running, pulling any resources for someone else will effectively put it on pause until the scheduler can give back the full capacity. And second, because these GPUs are distributed across multiple machines, running jobs on the cluster creates enough network traffic to slow down the data-intensive jobs. To prevent this, many users request that the GPUs used for their submission are consolidated into as few machines as possible.
“The paper refers to it as an all or nothing characteristic,” Chowdhury says. “You come in and say ‘I need 10 GPUs, and if you give me 10 GPUs I run; anything else, I don’t.’ That makes it a bit more difficult because now, if 10 GPUs aren’t present, you have to find other jobs behind it to skip to.”
And finally, a major obstacle to effectively scheduling deep learning jobs is that it’s difficult to determine exactly how long a given submission will have to run. Many of the jobs that researchers submit are testing different neural network models in search of the best one for their project, a task that can involve training 100s of models with unknown runtimes on their dataset. The best the submitters can usually do is provide a “loss curve,” a distribution of runtimes for that model that shows how long it might take.
Chowdhury’s Tiresias is a scheduler designed to minimize the average job completion time, taking this variety of constraints into account.
 Enlarge
EnlargeThe system first runs a brief profiling step on each job to determine whether it needs GPUs to be consolidated to fewer machines. Some models aren’t actually hurt by network communication – Chowdhury found that if the data structures (typically a very high-dimensional array called a tensor) in the model are roughly evenly sized, it can handle being run on distributed GPUs. If one tensor is significantly larger than the others, then that tensor will slow down performance wherever it’s stuck.
“We take the job and run it on a separate environment for a quick profiling,” Chowdhury explains, “to actually observe and identify the distribution of the tensor sizes. Once we decide it is heavily skewed, we will try to consolidate GPU allocation, and if it’s not we’ll find any free GPU and just put the job in.”
To actually schedule the jobs, Tiresias assigns high priority to every job by default, and a given job’s priority will gradually decline the longer it runs. This takes on the dual nature of deep learning training jobs – most will be researchers testing models in search of an effective one, which average short runtimes, and a few will be researchers running full training regiments on their chosen model, which can take days. The lower priority on long jobs gives them the ability to be interrupted, granting a spare minute of GPU use to a short test job.
“So at the level of the cluster,” Chowdhury continues, “we can schedule and allocate resources with basically no information that our users have to provide, or no assumption about how the network is going to behave – you can sit back and relax and it will get scheduled. “
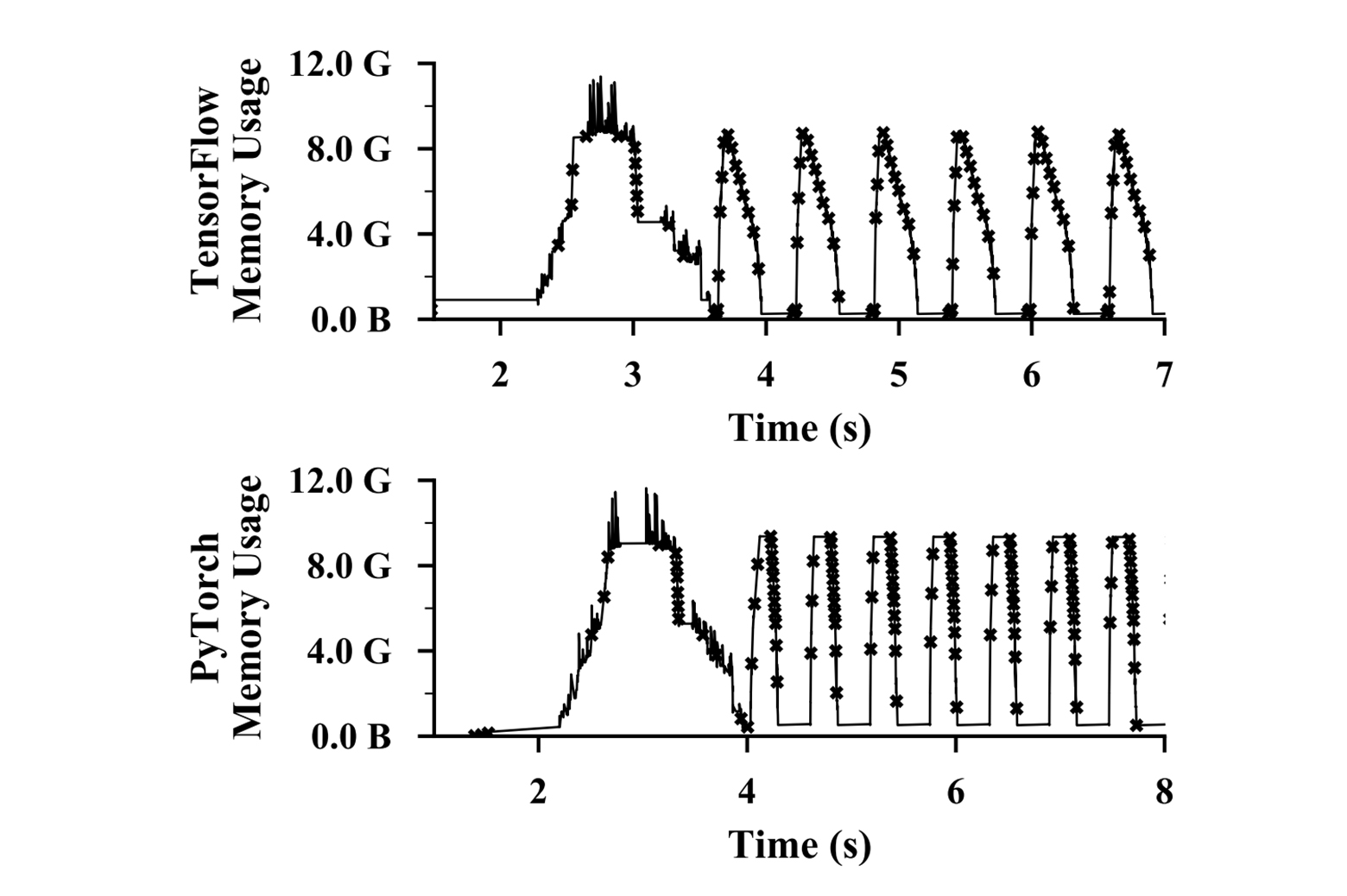
The team’s other system, Salus, is led by Peifeng Yu. It takes a novel approach to GPU scheduling, built on the observation that most deep learning applications never use the full memory or computation capacity of the GPUs they run on. In fact, many of these processes will use large amounts of GPU resources periodically, with noticeable gaps where very few resources are used.
 Enlarge
EnlargeThis turns out to be a major source of inefficiency – when jobs are submitted asking for a certain number of GPUs, they’re given the full capacity of each one.
What Salus does is include a software layer between researchers and the cluster that acts as a virtual GPU. This faux GPU accepts the job submissions, profiles them and their capacity demands, and “mixes and matches” them onto different shared GPUs. This arrangement is then submitted to the cluster for running.
This layer can have a huge effect on the aggregate performance of an entire cluster. While the extra step adds a 15-20% performance loss to each job, it can turn two 1 hour jobs that would take 2 total hours of GPU operation into a shared 1 hour 20 minute job, freeing up the second GPU for different tasks.
“We want to tell the researchers, ok you want 10 GPUs, but actually give them 7,” Chowdhury says. “So if I’m a cloud provider, I want to sell 120 GPUs when I only have 64 or 80. You can oversubscribe. On a job by job basis there may be some small performance loss, but on the aggregate the overall throughput of the system improves because more jobs will finish.”
Together, these systems fit in with Chowdhury’s goal of minimizing cost and expense at large data centers with minimal effect on their users.
“Too many resources are being wasted,” he says, “especially given that GPUs are so expensive today. And that scales – some of the smaller clusters we look at have over 2000 GPUs.”
Both the systems are available as open-source software at https://github.com/symbioticlab.